From Old-School Coding to AI Native: The Evolution of My Development Workflow 🚀
Shared on: June 1, 2026
Shared by: @Zhou Peng
From hand-writing code line by line, to using Copilot to speed up repetitive labor, to relying on Agents by simply describing requirements, software development is undergoing a fundamental transformation. A core question emerges along with it: when AI can write code that we cannot fully understand yet is functionally correct, will the value of developers move upward, or gradually disappear?
This article documents my complete journey from traditional programming to AI Native development, including how code readability gradually loses its grip, how testing becomes the new bedrock of trust, and how a developer's capabilities shift upward from "implementation expert" to "correctness designer." This is not just about tools—it is a firsthand witness to a paradigm shift in engineering.
Core viewpoint: code is degrading from a "carrier of knowledge" into an "intermediate artifact," while tests and constraints become the new engineering truth. Software engineering is moving from a craft industry to a manufacturing industry, and we stand right at this turning point.
One early morning last year, with the help of Claude Code, I completed a refactoring of a core module, involving changes to 47 files and nearly 5,000 lines of code. When I conducted the code review the next morning, I suddenly realized an awkward truth: I could only understand less than 30% of the implementation details. This should have been unsettling, yet all the tests passed and the functionality fully met expectations. In that moment, I clearly understood that something fundamental had already changed.
Three Evolutions
From the early "old-school coding" that relied on human effort as the only source of compute, to "Copilot" where AI assisted developers in boosting efficiency, to today's "AI Native" mode where AI leads production and developers set constraints. Throughout this evolution, the developer's role has gradually pulled away from concrete implementation details, continually moving upward to take on more decision-making and judgment tasks.

Old-School Coding
For a long time, like most developers, my workflow typically involved opening the IDE, understanding the requirements, designing a solution, and then writing code line by line. All the thinking, implementation, and debugging were concentrated in my head.
The bottleneck of this mode was not necessarily slow speed, but its high instability. When things went smoothly, I could keep making progress for days; but the moment I hit a knowledge gap (such as an unfamiliar low-level library) or a hard-to-solve bug, the entire development process would grind to a halt. From an engineering perspective, the human was the only source of compute in the system, yet also became the biggest point of risk.
What's worse, the cost of knowledge transfer in this mode was extremely high. A new team member needed weeks to understand the codebase; when something went wrong with the system, often only the original author could quickly pinpoint the cause. Code became the sole carrier of knowledge, and the human brain the only interpreter.
Copilot
The arrival of Copilot dramatically reduced repetitive labor. Boilerplate code, CRUD interfaces, type adapters, and the like could all be quickly generated through autocompletion. It was exhilarating at first—when writing a React component, I only had to type a function name, and the related useState and useEffect logic would unfold automatically.
But I soon realized this improvement did not touch the fundamental contradiction of development. Copilot did not understand the problem I was trying to solve; it could only speed up execution on top of the thinking I had already worked out. Decision-making was still entirely on the human; AI merely improved the efficiency of typing code.
It was like giving construction workers power tools—wall-laying got faster, but the architectural design, structural choices, and material allocation still had to be done by hand. The "physical effort" of coding went down, but the "mental effort" was not reduced at all.
Agent-Driven Development
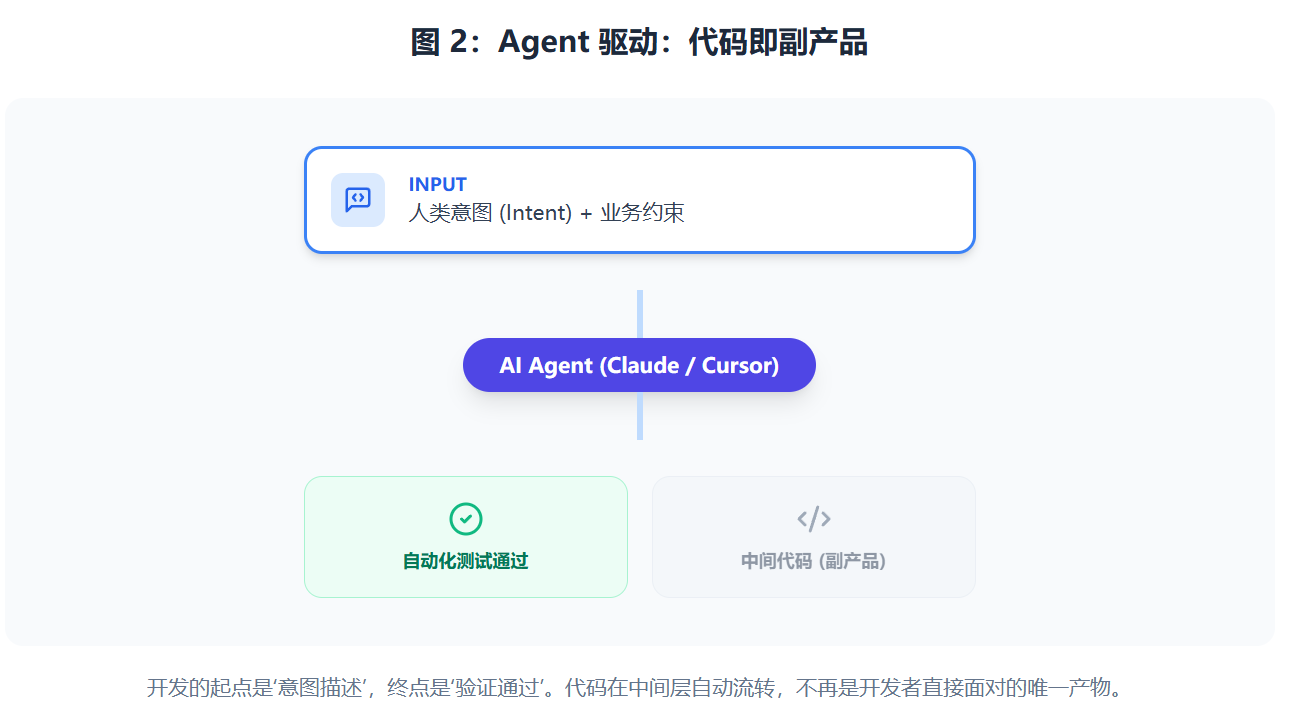
In this mode, development starts with an "intent description" and ends with "passing verification." After humans input their intent and business constraints, AI Agents (such as Claude, Cursor, etc.) automatically generate code and run tests. Code flows through this process; it is no longer the "final product" the developer directly faces, but merely an intermediate step toward reaching the goal.
The real turning point came after I started using Agent-driven tools like Cursor, Windsurf, and Claude Code. Development no longer begins with "how to write it," but starts from "what to do."
For example: last month I needed to add an "Export PDF" feature to a web application. In the "old-school coding" era, I would have gone through the following steps:
First, I would have spent about 30 minutes reading the documentation of the relevant PDF library to figure out the various interfaces and how to call them; second, about 20 minutes designing the data flow logic between the frontend and backend; third, entering the actual implementation phase, roughly 1 hour adapting and rendering page content into PDF format; finally, leaving 1 to 2 hours to handle all sorts of exceptions and style compatibility issues. The whole process was not only time-consuming but also heavily dependent on the developer's full participation and line-by-line coding.
With Claude Code, the entire process was simplified to:
First, clearly describing the requirement: "Add an export-to-PDF feature to the report page, preserve the existing styles, and support pagination." Second, the system immediately generated a corresponding implementation plan for me to review. Third, after running the initial tests, I found that Chinese fonts were missing, so I added a constraint: "Use Source Han Sans to handle Chinese." After testing again, the feature passed smoothly.
The entire process was compressed from the original 3–4 hours down to 40 minutes. More importantly, my role gradually shifted from "implementing the feature" to "judging whether the result meets expectations." The code itself also receded from being the final goal to being an intermediate artifact.
Irreversible Changes
As AI becomes deeply involved in coding, code readability gradually recedes into secondary importance, and engineering trust shifts toward "verifiability." Testing becomes the core language of human-machine collaboration; from requirement definition to behavior verification, verifiability is becoming the new foundation of trust in software engineering.
The Failure of Code Readability
As AI's involvement in the development process deepens, an increasingly prominent reality is: I find it harder and harder to understand the code AI generates.
This is not because the code itself is messy, but because AI's approach to solving problems is often different from a human developer's. It may use a library I'm not familiar with to solve a problem, refactor my originally imperative logic into a functional style, or even generate combinations of design patterns I've never encountered. At first, this made me quite uncomfortable—did I really write this code? Could I still truly control the entire system?
But after thinking it through calmly, I realized this phenomenon is not the first of its kind in the history of engineering. Today, most developers in fact don't fully understand:
- How a compiler converts a high-level language into assembly instructions
- How the V8 engine optimizes JavaScript execution
- How a GPU processes graphics rendering in parallel
- How CPU microcode concretely implements the instruction set
Yet none of this stops us from building extremely complex software systems. Engineering practice has long reached a tacit agreement: developers don't need to understand every low-level implementation detail; they only need to ensure the toolchain correctly executes the intended behavior. By the same token, code written by AI has essentially become a new generation of low-readability "intermediate layer." Just as we wouldn't refuse to program in high-level languages because we can't read assembly, future developers won't retreat to hand-writing code line by line just because they can't fully understand AI-generated code.
From "I Can Read It" to "I Can Verify It"
This shift brings a direct consequence: the way developers build confidence in a system has completely changed.
In traditional development, we mainly gained trust by reading code:
- Understanding the internal logic of every function
- Knowing the lifecycle of every variable
- Being able to reason about all possible execution paths
We believed that as long as we could understand the code, the system was correct. This was trust based on "transparency."
However, under a development mode with deep AI involvement, this path is gradually failing. The new logic of trust is:
- I don't need to understand exactly how it's implemented
- But I must be able to confirm whether its behavior meets expectations
- Trust is built through tests, monitoring, and interface contracts
This is trust that turns toward "verifiability." The focus of engineering is shifting from the readability of code to the verifiability of system behavior.
From After-the-Fact Inspection to Continuous Feedback
Precisely because "reading code" is no longer reliable, testing has been elevated to a central position in AI Native development. It is no longer merely a verification step before going live, but a continuous feedback system running through the entire development process.
In my current workflow, testing primarily plays the following three roles:
Constraint Boundaries
Through static type checking, ESLint rules, API Schema definitions, and other means, we set clear boundaries for AI's code generation. AI can implement freely within this range, but cannot cross the line.
Functional Definition
Unit tests and integration tests clarify "what is correct behavior." Many times, I don't write the implementation code directly; instead, I first write test cases, then hand them to AI to complete the functionality and ensure all tests pass. The tests themselves become the specification, while the code is its proof of implementation.
Unexpected-Behavior Probing
Fuzz testing, property-based testing, stress testing, and the like can cover paths the developer never thought of. AI-generated code may handle edge cases I missed, but may also introduce unexpected side effects. These "emergent behaviors" are exposed through testing.
More importantly, once a test fails, I usually don't need to fix the code myself. I just hand the failing test case along with the relevant error logs and stack traces to the AI, letting it adjust on its own according to the established constraints. This feedback loop can iterate over multiple rounds until all tests pass.
The Truth Exposed by Test Failures
Under this development mode, I gradually came to recognize an important change: many times, the reason a test fails is not that the AI wrote the code wrong, but that the requirement, constraint, or description itself is flawed.
A classic case came up last month: I asked the AI to implement a "user permission-check middleware" and wrote several test cases for it. The first two cases (admins can access all endpoints; regular users can only access their own data) passed smoothly, but the third case (guests can access public content) failed. My first reaction was "the AI misunderstood," but after careful investigation, I found the problem lay in my own inconsistent definition of "public content":
- In the requirement description I wrote "public content requires no login"
- However, in the database Schema, the default value of the "public" field was set to
false - In the test data, the
publicfield of most content was indeedfalse
The AI strictly implemented the business logic according to the Schema, while my test case was based on an inaccurate assumption. This test failure actually exposed an internal contradiction in my own expectations of the system's behavior.

At a time when humans cannot fully read the vast amounts of AI-generated code, the foundation of trust is shifting from code readability to system verifiability. Testing has become the new source of truth.
This made me deeply realize: on the surface we are testing code, but in reality we are verifying whether the AI has truly understood our intent. Test cases, error logs, and type constraints have become the most reliable and effective language of communication between humans and AI.
The Repositioning of Developers
In the AI era, a developer's value is moving upward from "implementation expert" to "correctness definer," with core competencies shifting toward requirement structuring, constraint design, and system verification. Technical barriers are being broken down, and the division of labor is organized by responsibility rather than tech stack. The real challenge lies in balancing AI empowerment with self-reliant capability, and maintaining ultimate control over the system.
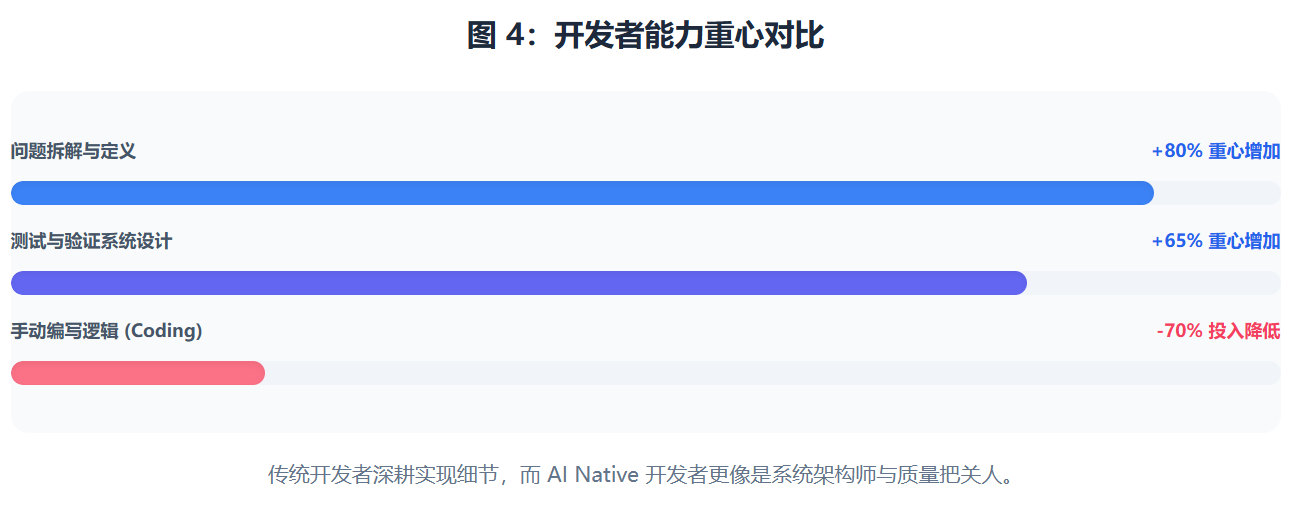
Capability Shift: From Implementation Expert to Correctness Designer
As code itself ceases to be the core embodiment of capability, a developer's value gradually moves upward from the implementation layer to the design and constraint layer.
In the traditional context, a top developer was often defined as an "implementation expert," distinguished by their coding speed, their proficiency with specific frameworks, and their ability to hand-write complex algorithms, with vast amounts of API documentation and best practices stored in their head.
However, in the AI Native era, these once-formidable skills are being rapidly commoditized. In their place comes a restructuring of developer capabilities across four dimensions. First is the ability to structure problems—whether one can decompose vague business requirements into logical subsets with clear boundaries. Second is the ability to define correctness—in the face of a black box that generates results, accurately describing "what is correct" matters more than "how to implement it." Third is the ability to design feedback systems—constraining AI's output by building a rigorous testing and monitoring system. Finally is systems thinking—coordinating the boundaries and interaction contracts between modules at a higher level.
Take sorting algorithms as an example: the value of a traditional master lies in being able to implement a red-black tree by hand, knowing every low-level detail; whereas the pioneers of the AI Native era focus on defining constraints such as stability, time-and-space complexity, and memory limits, then use AI to quickly generate multiple implementations and verify them through automated testing.
The value of the former lies in "implementation ability," the value of the latter in "definition ability." When AI can implement any clearly defined requirement, defining the requirement itself becomes the scarce and critical capability.
The Division of Labor of the Future: No Frontend or Backend, Only Boundaries of Responsibility
As AI technology advances at breakneck speed, the technical barriers between frontend, backend, and infrastructure are being gradually broken down, and the logic of the division of labor in development is being restructured accordingly—shifting from "who is responsible for writing which kind of code" to "who defines the goal, who sets the constraints, who is accountable for the final result."
I once witnessed a product manager who was not familiar with React or TypeScript, yet could skillfully use Cursor to produce frontend features that could be deployed directly to production—not just toy demos meant for show. What enabled her to make this leap was not programming skill, but her precise grasp of product logic: she knew exactly what information users should see on the interface, clearly understood what flow each interaction should trigger, and could accurately define how the system should communicate feedback to users when something went wrong.
In this process, AI served as the bridge for code implementation, transforming her business intent into runnable software modules. Her role transformation was, in essence, not "learning to program from scratch," but directly taking control of the critical path from intent to implementation in the capacity of someone "accountable for the product's final behavior." What this reflects is a new logic of division of labor in the AI era: people who understand the business are, with the help of tools, becoming the direct builders of features.
The future structure of development division of labor may take on a clearer separation of rights and responsibilities: product owners focus on defining user experience and business logic, directly using AI to implement product prototypes and drive continuous iteration; system owners focus on architectural design and setting performance metrics, using AI to generate technical implementation plans and build full-chain verification systems; security owners work around threat models and protection strategies, leveraging AI tools to conduct code audits and fix vulnerabilities.
Under such a trend, mastery of the tech stack will no longer be a practitioner's "moat." The true core competitiveness will ultimately return to a deep understanding of business goals and a precise ability to control system behavior.
Risk and Balance: Don't Lose the "Ability to Exit"
However, this transformation also comes with risks that cannot be ignored.
The foremost risk is that over-reliance may lead to capability atrophy. If one relies entirely on AI to generate code, a developer may gradually lose the core ability to build functionality from scratch. Once the tools fail, it's like a driver accustomed to relying on GPS suddenly losing navigation—unable to even read basic road signs. For this reason, we need to maintain the "ability to exit": hand-implement at least one small feature every month, continuously read AI-generated code to understand its design logic, and hand-write or deeply review the code on critical paths.
Second, insufficient testing can easily bring a false sense of security. When we replace "code readability" with "tests passing" as the basis for trust, the quality of the tests themselves becomes especially critical. Inadequate test coverage can lead to a misjudgment of the system's real risks. Therefore, one should establish a robust verification system, ensuring branch coverage of core logic exceeds 90%, equipping critical paths with integration tests and end-to-end tests, and proactively exploring unexpected behavior using methods such as fuzz testing.
Finally, a holistic understanding of the system may be lost. When every module is generated by AI, developers can easily lose their grasp of the system's overall architecture and operating mechanisms, which in turn leads to architectural decay and the accumulation of technical debt. To meet this challenge, one should continuously maintain a panoramic understanding of the system, keep high-level architecture documents updated, and clarify module responsibilities and dependencies; after each major change, use AI to generate architecture diagrams supplemented by manual review; and periodically conduct "architecture health checks" to identify circular dependencies and modules with unclear responsibilities.
The key lies in seeking balance: we must both fully harness the leap in efficiency that AI brings and always retain the ability to take over the system and solve problems independently when necessary. In an AI-empowered era, true professionalism is reflected not only in knowing how to use the tools, but more so in knowing when and how to go beyond them.
Conclusion: When Code Is No Longer Readable, Feedback Is the Only Truth
Returning to that initial scene: faced with nearly 5,000 lines of code generated by AI refactoring, I could not understand every implementation detail line by line, yet the system ran stably and all tests passed. This was not an accidental anomaly, but a clear signal—software engineering is moving from the "age of craftsmanship" to the "age of manufacturing." Just as a modern auto worker need not be versed in the materials science of every part, future developers will not need to scrutinize the implementation logic of every line of code.
Our core value is undergoing a fundamental migration, no longer confined to the single dimension of hand-writing code, but turning toward deeper product-value creation: first, defining the standard of a "good product"—anchoring the system's core goals and clear boundaries through requirement clarification and constraint setting; second, building a full-chain quality inspection system—relying on scientific testing strategies and routine monitoring mechanisms to ensure deliverables precisely match expectations; and ultimately, we will bear full responsibility for the verifiable correctness of the product.
AI Native does not diminish the role of developers; rather, it propels us to leap from "coding executor" to "correctness definer." When code is no longer the only window into understanding the system, testing and continuous feedback become the reliable basis for judging the system's true state.
The quality of future software will no longer depend on the experiential intuition of individual developers, but rather on:
- Whether requirements are defined clearly and unambiguously
- Whether tests provide sufficient coverage and effective verification
- Whether feedback forms a continuous closed loop that truly drives improvement
In short:
AI is responsible for generating code; humans are responsible for setting constraints.
AI is responsible for implementing features; humans are responsible for defining what is correct.
This may mark the deepest division-of-labor transformation in the field of software engineering. And we stand at the very beginning of this historic turning point.